Visualizing Migration in Football: Scraping Data
Feb 08, 2023
In the previous post in this series, I introduced my project and laid out some specifications for the data that I’m planning to use. Now it’s time to dive in and scrape the data off of the Transfermarkt website using Scrapy.
Scrapy is a Python library that is typically used for large-scale data scrapes. It has a large amount of useful features, including built-in caching, asynchronous requests with Python’s web framework, user-agent randomization, and more.
This was my first time using Scrapy for a personal project, and I thought that it was fairly straightforward and even fun to use. In this post, I will go through my full scraping process from the planning stages to the finished product. I'm not going to give a ton of background on Scrapy here but check out my full Scrapy beginner’s guide if you want to read up on how Scrapy works and how to get it set up.
Finding the Data
In the initial stages of locating and scraping data, I like to click through the website and ask myself the below questions:
- What data will I need?
- What are the URLs for the pages I will be scraping? Are there any shortcuts I can take by manipulating the URL subdirectories or parameters?
- Where are the individual data values located on each web page?
- How can I structure my functions to make the least amount of Scrapy requests possible?
- What should my target JSON data item(s) look like?
Let's go through these steps together.
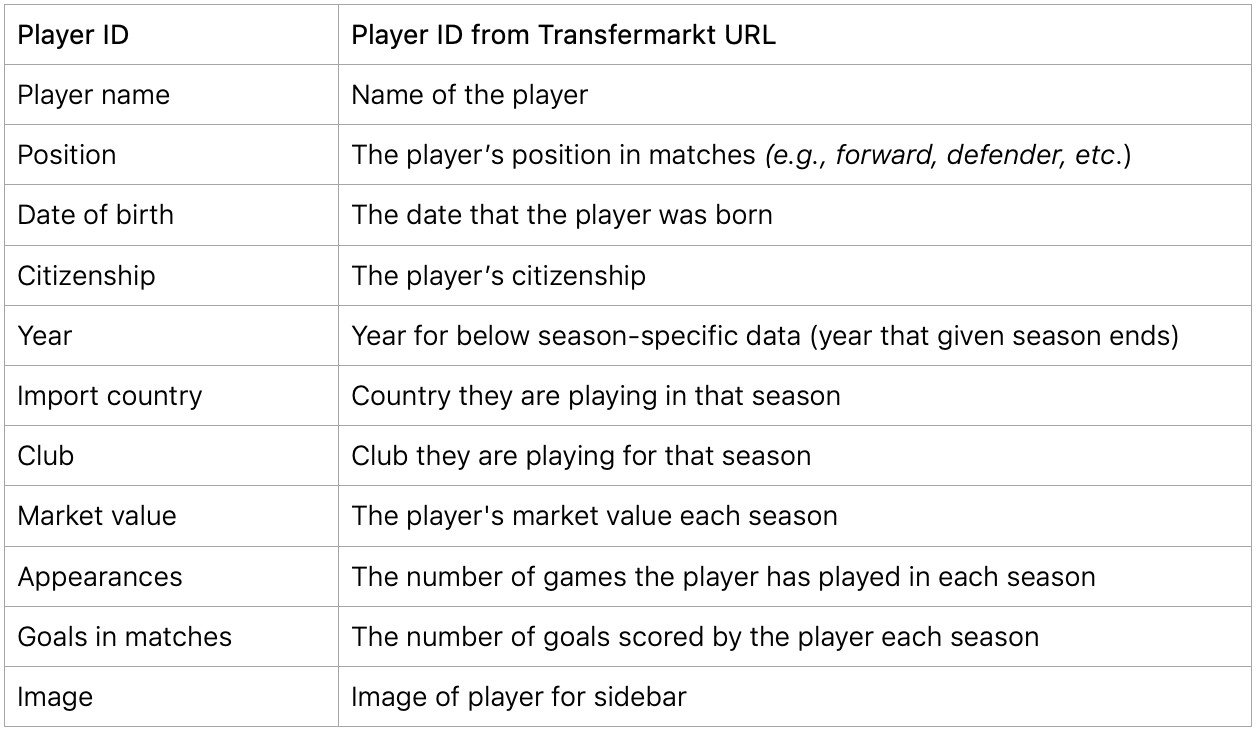
Step 1: Data Definition Recap
The previous post in this series ended with the below table that we're going to use as a guideline for the scraping process. The plan is to scrape the below information for each player that played in a foreign league from year 1994 to present.
Step 2: Locating Data & Page URLs
Transfermarkt is a pretty complicated website that provides tons of options for filtering and obtaining player data. After some exploration, I came up with the below plan to move through the necessary pages and scrape the information we need.
First, we navigate to every available country page and get the URL for their first tier league.
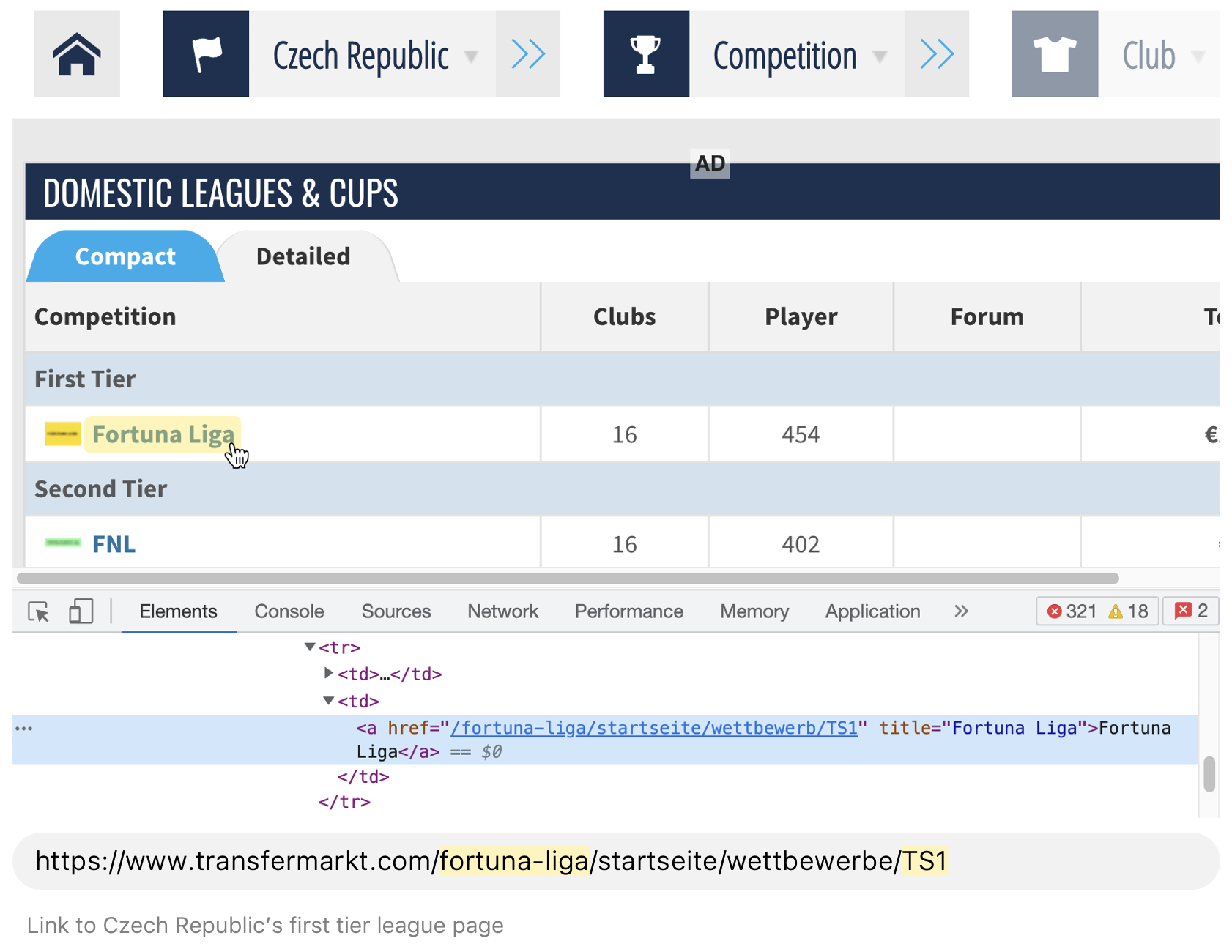
Conveniently, every league page has a link to a table with the league’s foreign player data. The league page and foreign player page URL's are nearly identical with the exception of one subdirectory value (highlighted purple below). To save on time and avoid scraping the foreigner link value from each league page, we can simply tweak the URL a bit and make a new request to each league's foreign player page.
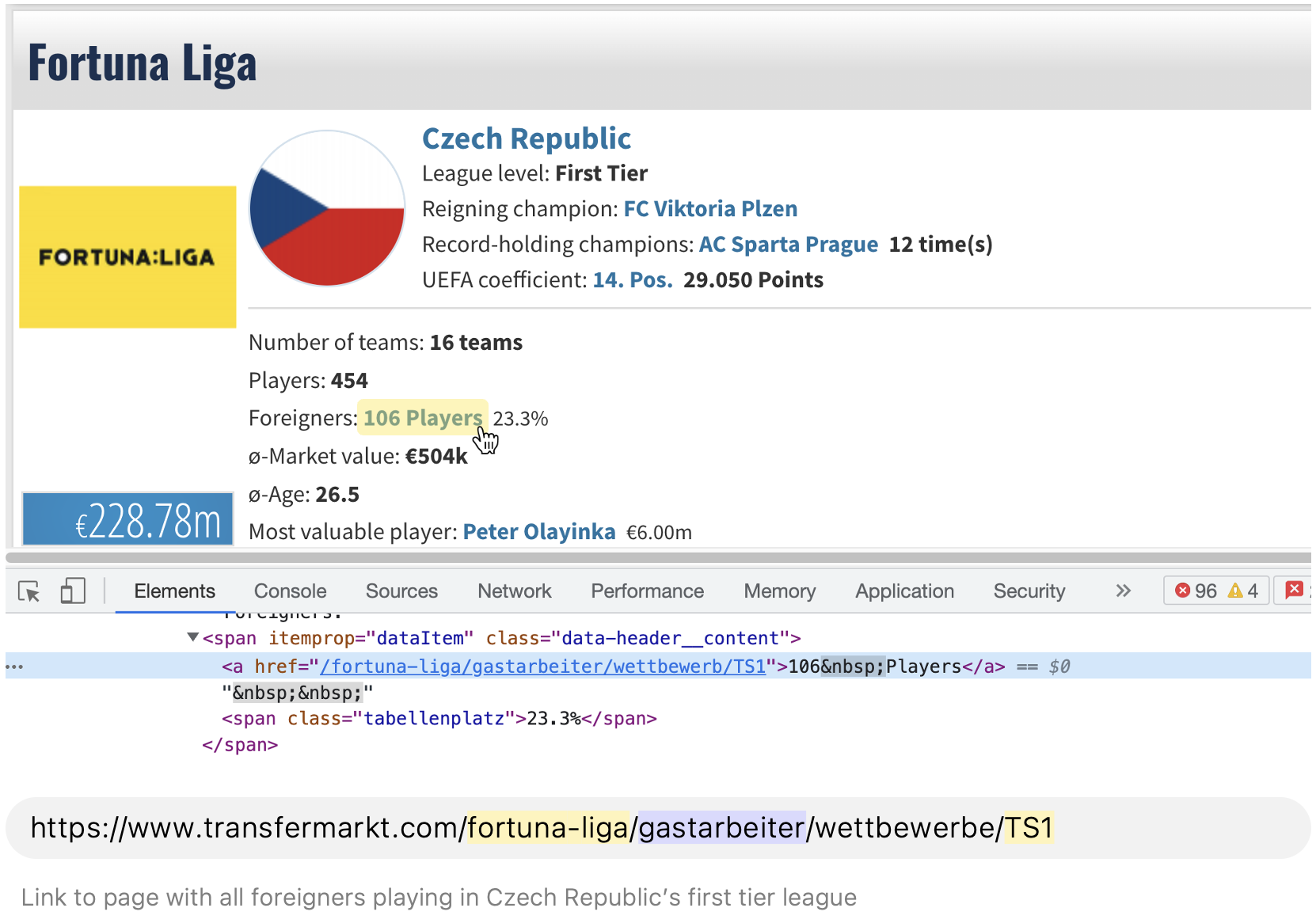
Inspecting the foreign player page, we can see that there are a couple of dropdown menus that allow the user to select a year and country with which to filter the foreign players. We can first scrape those years and country ID's and then use them to dynamically generate URL's with a combination of every valid year and country, making a new request to each URL.
During this iteration process, we can filter the year values to stay within our desired date range of 1994-2023. We will also have to filter out the country code of the import country we're currently scraping info for, so that we only get lists of foreign players.
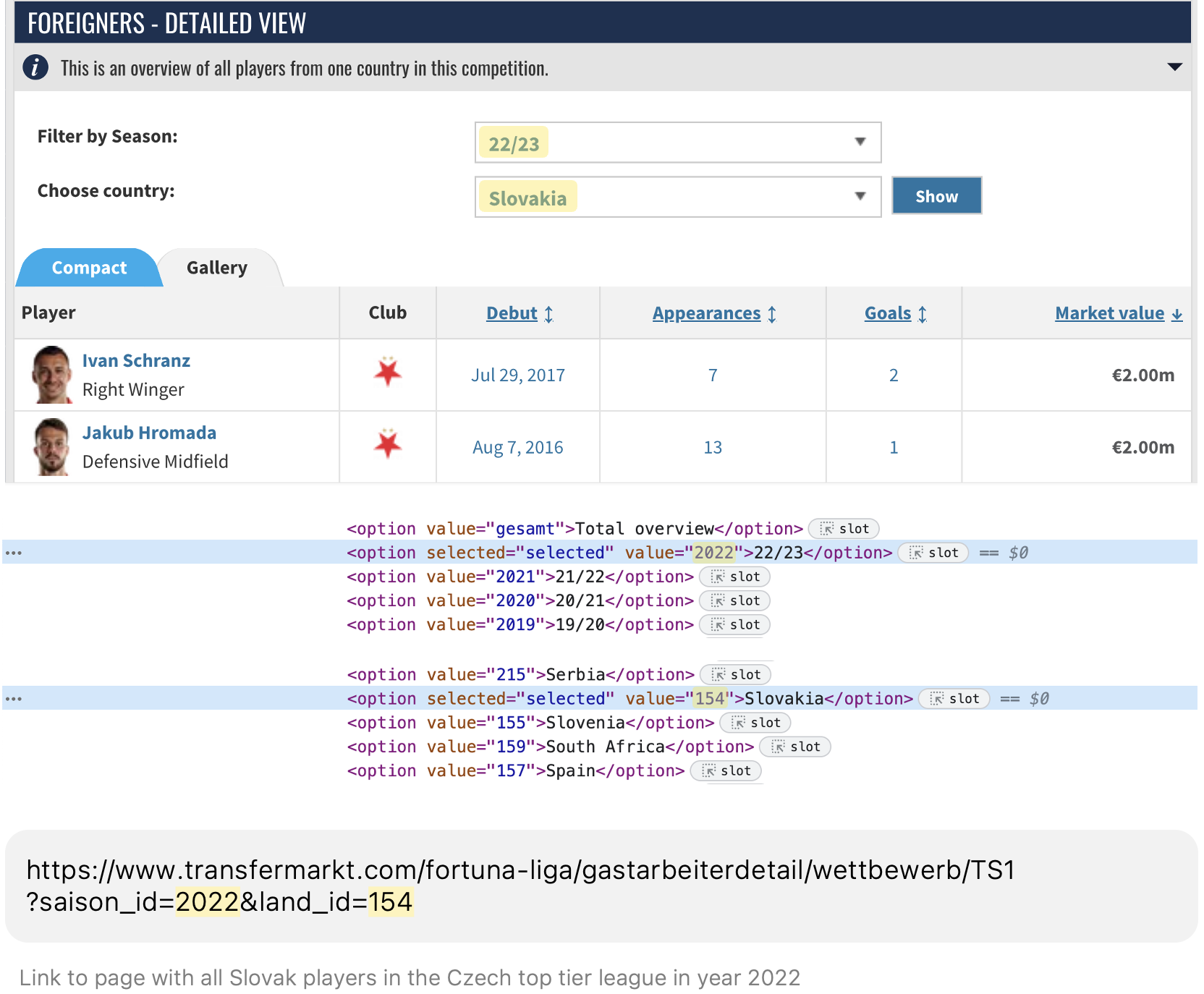
The resulting player list pages appear to have a lot of the player information that we need, including player name, player ID, player URL, import country, club, goals scored, appearances, and market value. We can scrape that information from this page and then we just need to go one step further and follow the player links to the player detail pages for the rest of the necessary data (date of birth, citizenship, position, and player image).
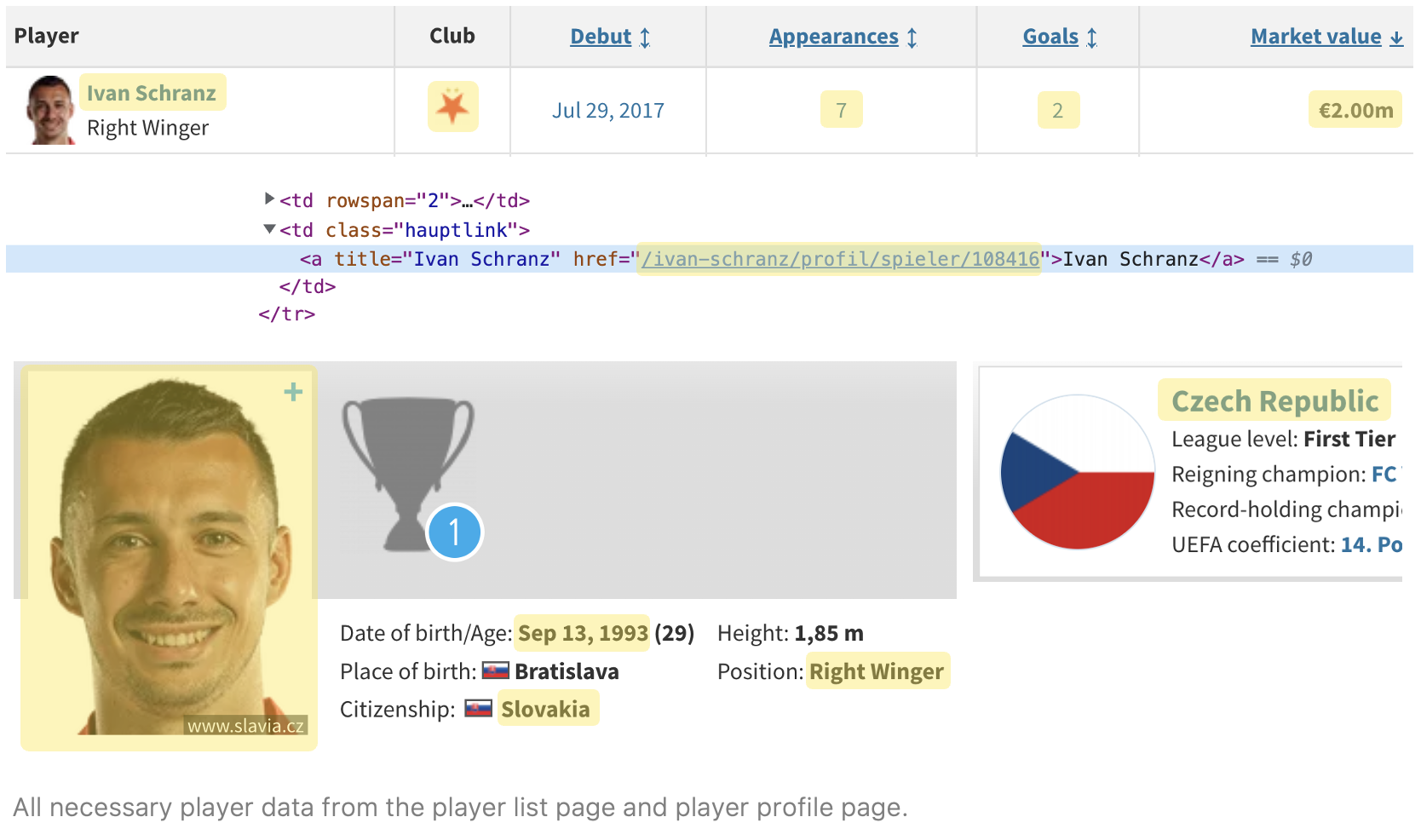
Step 3: Creating Target JSON Object(s)
Normally, coming up with a target JSON object would be as simple as taking the initial data definition and putting it into JSON format. This project, however, presents a unique challenge, as is likely that we will come across the same player multiple times on player lists for different years.
The player stats (goals, appearances, market value) change annually and need to be scraped separately for each year, but some of the other data (DOB, position, player image) will not change year by year.
We can avoid re-scraping the static data every time we come across the same player by splitting the process up into two spiders. The first spider will scrape the player ID, player page URL, and all annual stats for each year. When all of that data has been successfully scraped, we can then extract a list of all player URL’s from the resulting JSON object and convert it into a set to get unique values. Passing in our list of unique player page URL's as the second spider's start_urls value, we can then scrape each player profile page just once. This should significantly increase the speed of the overall scraping process and it will be easy to combine these data sets when we clean our data in the future.
Using this method, we can structure the two target JSON objects as follows:
// Player stat spider target object:
{
"player_id": 5658,
"year": 2012,
"citizenship": "Czech Republic",
"import_country": "England",
"club": "Chelsea FC",
"appearances": 34,
"goals_scored": 0,
"market_value": 25000000,
"player_url": "/petr-cech/profil/spieler/5658"
}
// Player detail spider target object:
{
"player_id": 5658,
"name": "Petr Cech",
"date_of_birth": "May 20, 1982",
"image_urls": [
"https://img..."
],
"player_image": "full/5253e1fb582bf53663eb9e07ad9c4e689c38f5a2.jpg",
"position": "Goalkeeper"
}Creating Spiders with Scrapy: The Interesting Bits
With a plan in place, the next step was to build out the two spiders. This post is getting long, so I won’t do a line by line explanation of all of the code, but I do want to quickly touch on some of the interesting challenges that came up. You can find the full code for the player stat spider here and the player detail spider here.
Chained Requests and Pagination
Any project involves scraping from multiple subpages or dynamically generating URLs to scrape will likely call for multiple parse functions with chained Scrapy requests. This is actually pretty easy to accomplish - instead of yielding an item at the end of the initial parse funciton, just create and yield a new request, as demonstrated below. The new request takes your new target URL, a callback to a new function to process the next page's data, and any metadata that you want to make available in the callback function.
def parse(self, response):
# ...
request = scrapy.Request(
url = 'https://www.transfermarkt.com' + foreign_player_list,
callback = self.parse_list_urls,
meta = {
'item': PlayerStatItem()
})
yield request
def parse_list_urls(self, response):
# ...A similar pattern can be applied to dealing with lists that include pagination (such as some of the foreign player lists on Transfermarkt).
First, select the page’s “next” link that you would use to navigate to the next page. Create a conditional to only run the callback if a next page still exists. This should ensure that the callbacks stop when we reach the end of the list. Next, add the next_page link to the current URL using response’s urljoin method. Finally, create and yield a new request, passing the current parent function in as the callback and next_page as the URL.
def parse_list_urls(self, response):
# ...
next_page = response.xpath('//*[@title = "Go to next page"]/@href').extract_first()
if next_page is not None:
request = scrapy.Request(
url = response.urljoin(next_page),
callback = self.parse_list_urls,
meta = {
'item': item,
})
yield requestLoading in JSON Data
After scraping the player stats, we needed to get all of the player URL’s just once to use in the player detail spider. A simple way to do this is to load in the player stat JSON object, iterate through each row, and add each URL to a an array. The array can then be converted to a set, in order to make the values unique. I had to do a little Googling to figure this out, so I wanted to include the code below. It’s pretty simple and just uses Python’s built in open function as well as the json module’s load function to load in the data.
f = open('../data/player_stats.json', encoding='utf-8')
data = json.load(f)
url_list = []
for i in data:
url_list.append('https://www.transfermarkt.com' + i['player_url'])
f.close()
start_urls = set(url_list)Image Pipeline
Scrapy pipelines provide a way to postprocess items that have been scraped. You can write your own pipelines or make use of predefined ones such as the ImagesPipeline that was used for this project. The ImagesPipeline shown below has two main methods, get_media_requests, which generates the reqeusts for the image URL's, and item_completed, which is called after the requests have been consumed.
class PlayerImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
image_paths = [img['path'] for ok, img in results if ok]
if image_paths:
item['player_image'] = image_paths[0]
return itemThe get_media_requests function takes any image URLs scraped by the player_detail_spider and generates an HTTP request for their content. After the image URL requests have been made, the results are passed on to the item_completed method.
Within the item_completed function, a list comprehension filters the list of result tuples (of form [(True, Image), (False, Image) …] for those that were successful and stores their file paths relative to the directory specified by the IMAGES_STORE variable in settings.py.
Finally, we pass the image to a Scrapy item adapter, which provides a common interface for working with item types.
Now that that’s set up, go to settings.py to enable the pipeline and specify a directory to which you want to save the images:
IMAGES_STORE = 'images'Finally, back in the spider, use the following code to overwrite the default pipeline. This will ensure that all image data is processed through the custom image pipeline:
custom_settings = {
'ITEM_PIPELINES': {'football_vis.pipelines.PlayerImagePipeline': 300},
}The Market Value Struggle
Last but not least, I want to shoutout Transfermarkt for making it incredibly difficult to scrape player market data values by year. This challenge was very specific to this project but it was a struggle, so I wanted to include it in hopes that it might help someone someday.
At first glance, it seems that scraping player market values would be very easy as they appear in the foreign player list below:
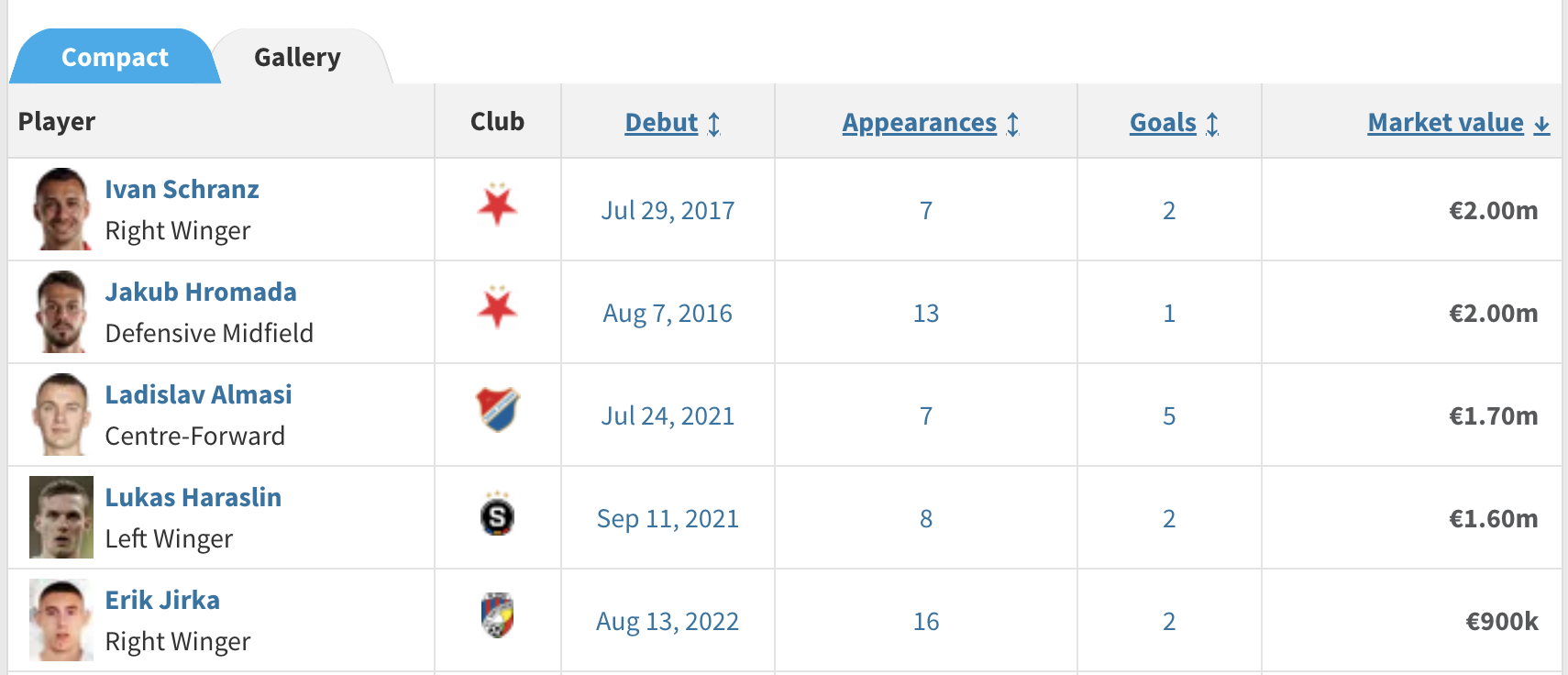
The problem is that this seems to be a new feature for 2022, and the market value data is excluded from the tables for all other years. The only other place where player market value is listed by year is on the player profile pages, in a very Scrapy-unfriendly chart format:
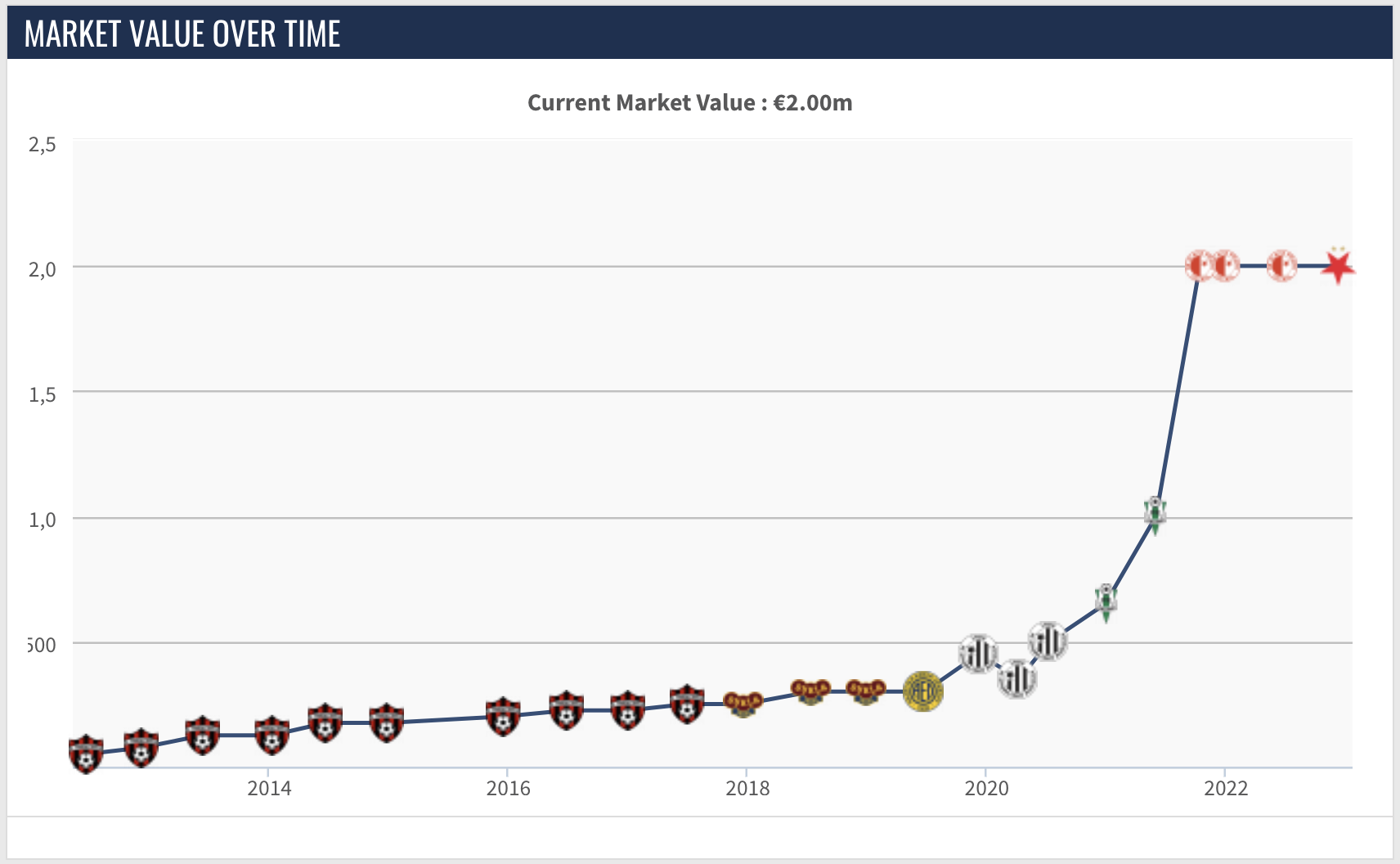
Luckily, the chart data is listed in the page source. It’s not pretty, but with a little bit of help from Pandas and NumPy, the below code extracts the market value chart data into a dictionary with the keys being the year and the values the market value. I will need to merge this information back into the data from the player_stats_spider, so I figured that a dictionary would allow for quick access in my data processing stage but the chart data can be easily manipulated into whatever format you need.
script = response.xpath('//script[@type = "text/javascript"]/text()')
idx = np.where(['/*<![CDATA[*/' in x[:20]
for x in script.extract()])[0][-1]
script = script[idx].extract()
mv_section = script.find(
"'series':[{'type':'area','name':'Marktwert','data':[")
if mv_section > 0:
table = script.split(
"'series':[{'type':'area','name':'Marktwert','data':[")[1].split(']')[0]
table = pd.DataFrame(literal_eval(table))
table = table[table.datum_mw != '-']
table['datum_mw'] = pd.to_datetime(table['datum_mw'])
table['datum_mw'] = table['datum_mw'].dt.year
table = table.rename(columns={'y': 'value', 'datum_mw': 'year'})
table_dict = table.to_dict(orient='list')
market_value = {}
for i, year in enumerate(table_dict['year']):
market_value[year] = table_dict['value'][i]
data['market_value'] = market_valueDebugging and Testing
There are not many things more satisfying than successfully scraping 199,555 rows of data but the process of getting everything to work takes a little bit of tinkering, and with such a large dataset it can be a challenge to confirm that you have all of the data that you intended to scrape.
Before I wrap this up, I want to mention a couple of little tricks that helped me out in my debugging and testing process.
Debugging
Since Scrapy is run from the terminal, it’s default logging is done in the terminal as well. When you have hundreds of items being scraped per minute and errors flying at you left and right, it can be hard to keep track of everything in the terminal. Adding the below lines to the settings.py file can output the logging information to a separate file that you can inspect at your leisure:
LOG_FILE = 'errors.log'
LOG_LEVEL = 'INFO'You can use LOG_FILE to provide a filename for the logging output. LOG_LEVEL can be set to one of the following values which specify the severity of the logs you want to see: CRITICAL (most severe messages only), ERROR, WARNING, INFO, DEBUG (shows you pretty much everything that’s going on). I found INFO to be the most useful as it let me know when errors came up, but suppressed all other details other than the number of items scraped per minute and process details when starting and closing the spider.
Testing
This is going to sound pretty obvious, but one thing that helped me a lot in my testing process was to work with small subsets of data first, manually adjusting my country and year ranges to only scrape data from one country and one year initially. Trying to scrape every piece of data everytime you want to test and iterate on your code can get annoying. One other thing I didn’t know at first was that you can stop a spider by pressing ctrl + C twice if you do get stuck in a neverending exception rabbit hole.
One other thing that I found useful for this project specifically was to create a mini-spider that scraped the foreign player count for each country and added all of the counts together. This gave me a target count of 199,555 players so that I could make sure my final dataset was complete. I also used the dataset from my mini-spider to do a little bit of initial data exploration and check that there were enough numbers from each year just in case there was too little data from the 90s. It turns out there was a good amount of data from that time, and I think that the large date range will provide some interesting insight, so I kept my range as is.
These fairly manual testing methods are pretty high level and I plan to write some real unit tests soon. At that point, I'll update this section with those details.
Final Files & Next Steps
If anybody has read this far, I’m honestly incredibly impressed. I know this was a long one, but I hope that there are some useful tidbits in here. You can access the full Github repository for the scraping part of this project here.
In the next post in this series, I will discuss the process of cleaning and exploring the player data with Pandas and NumPy.
Comments (0)
Created by Zoe Ferencova